Back to blog
Ashley Rich
Technical
Laravel Multi-Region Queues with Horizon
Recently, we rolled out an additional test region in DeploymentHawk, located in Chicago. This is an important feature for our customers across the Atlantic because it addresses one of the biggest issues with performance auditing tools: score variance. Score variance is that enigma where your site’s performance score drops quite significantly between audits for no apparent reason.
Score variance is a common problem with performance auditing tools due to the inherent variability in how websites are delivered to users. One of the biggest culprits is network latency, which is the time it takes for data to travel across the network. Simply reducing the physical distance between the test agent and the location of the site being audited will often give more consistent performance scores. Our US customers can now test in the Chicago region eliminating the need for a transatlantic hop.
In this article, we'll dive into how we implemented this in Laravel using Horizon.
#Our Infrastructure
We’re not using fancy infrastructure, like autoscaling or serverless. We’re using plain old virtual servers on Akamai (formerly Linode), provisioned and managed using Laravel Forge. By provisioning our own servers, we have full control over the hardware. Choosing dedicated vCPUs is crucial for delivering consistent performance and is another key factor in minimizing performance score variance.
This is how our old infrastructure looked before implementing multi-region support:
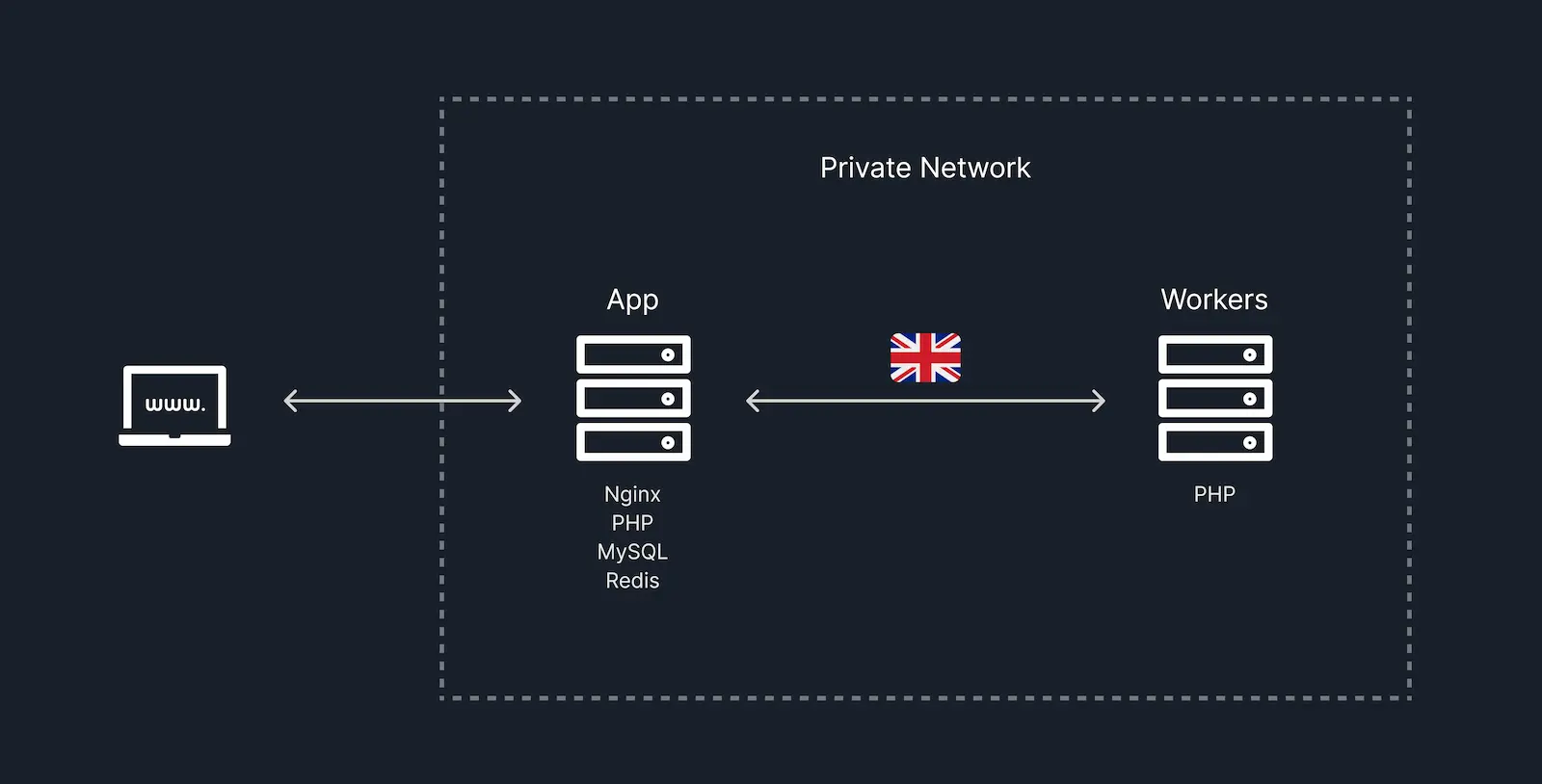
For simplicity’s sake, I’ve included only a single worker in the diagram, but we had multiple workers in reality.
Our app server hosts everything, including MySQL and Redis. One important thing to note is that no Horizon processes were running on the app server. All jobs, including those pushed to the default queue, were processed on the worker servers, which pull from the app server’s Redis queue connection. You’ll see why that’s relevant below.
Our new infrastructure is very similar to the old one; the only difference is that we now have additional workers in a different region outside of the private network.
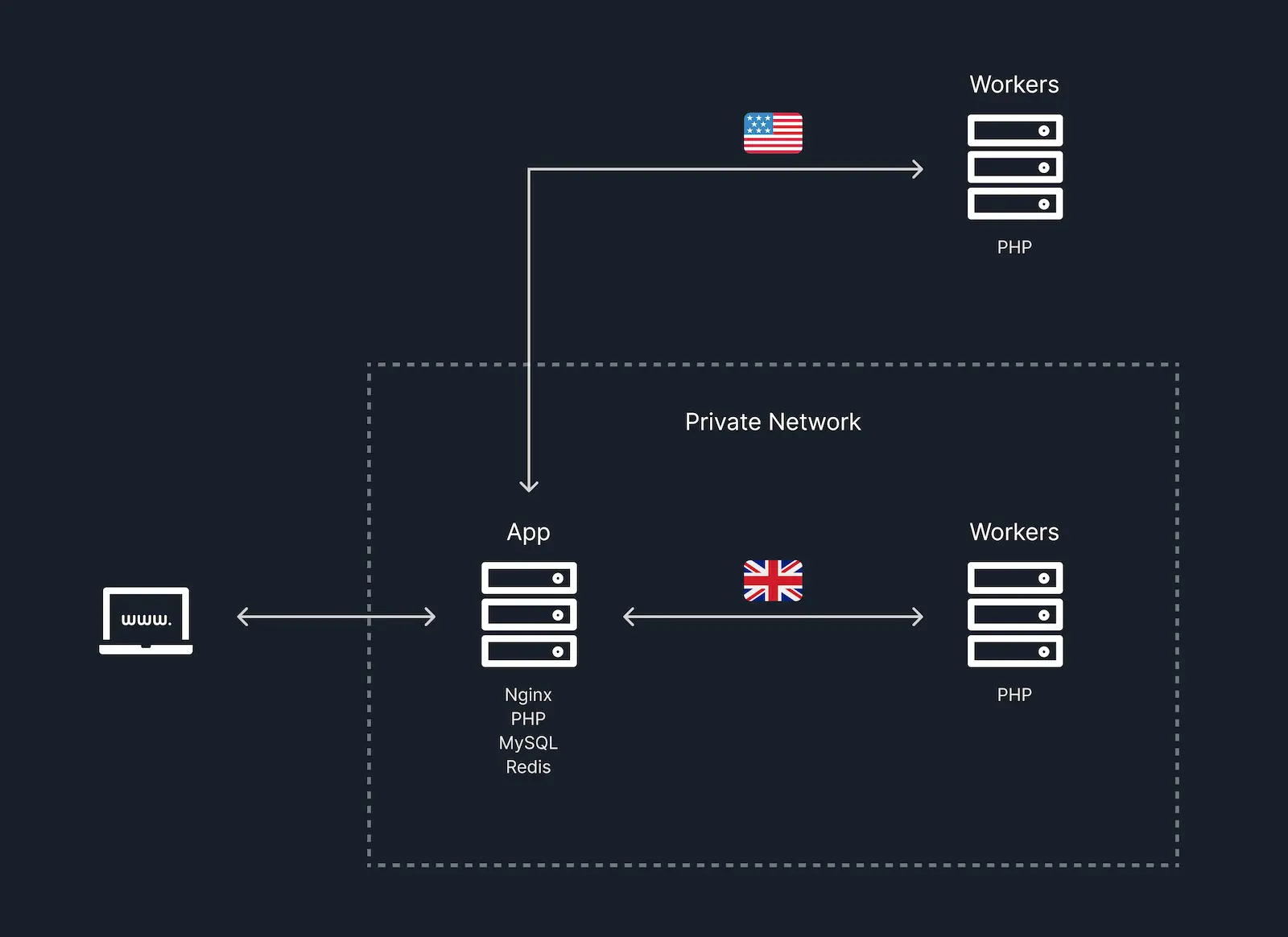
#Network Config
Our app server was already configured to allow external access to MySQL and Redis by changing their bind addresses. This allowed the existing worker servers to connect to the database, cache, and queue connections. To prevent unauthorized access, firewall rules allowed only connections from the worker server’s IP addresses on ports 3306 (MySQL) and 6379 (Redis).
Our London worker servers connected to the app server over the internal private network, which is important because data transfer is free within the private network. This was achieved by updating the worker servers .env file to point to the app server’s private IP address:
DB_HOST=192.168.*.*
REDIS_HOST=192.168.*.*For each of the new Chicago worker servers, firewall rules were added to the app server to allow connections on ports 3306 and 6379. Their .env files were updated to point to the app server’s public IP address.
#Horizon Config
With our new Chicago worker servers ready to start accepting jobs, we need to consider our Horizon config. It’s worth noting that the Horizon processes haven’t been started on the new workers yet, as they would start pulling jobs from the audits queue, which isn’t what we want.
Previously, our config was simple, with just two queues: default and audits. Here’s how our horizon.php config file looked:
'defaults' => [
'supervisor-1' => [
'connection' => 'redis',
'queue' => ['default'],
'minProcesses' => 1,
'maxProcesses' => 2,
...
],
'supervisor-2' => [
'connection' => 'redis',
'queue' => ['audits'],
'minProcesses' => 1,
'maxProcesses' => 1,
...
],
],
'environments' => [
'production' => [
'supervisor-1' => [],
'supervisor-2' => [],
],
],
We have two separate “supervisors” because we don’t want the audits queue to be balanced. We only want 1 process accepting audit jobs, so they’re not running concurrently on any given worker server. For context, the job pushed to the audit queue does a bunch of legwork, including launching Google Chrome and running Lighthouse. As mentioned above, performance score variance is a big issue, and not running Lighthouse audits side-by-side goes a long way to fixing that due to less resource contention.
With that in mind, this is how our new horizon.php config file looks:
'defaults' => [
'supervisor-1' => [
'connection' => 'redis',
'balance' => false,
...
],
],
'environments' => [
'production' => [
'supervisor-1' => [
'queue' => ['default'],
'maxProcesses' => 4,
],
],
// Chicago
'us-ord' => [
'supervisor-1' => [
'queue' => ['us-ord:high', 'us-ord'],
'maxProcesses' => 1,
],
],
// London
'eu-west' => [
'supervisor-1' => [
'queue' => ['eu-west:high', 'eu-west'],
'maxProcesses' => 1,
],
],
],
We’re now only using a single “supervisor” but have introduced additional environments. Each environment now listens to a specific queue. For our regional environments, we’ve added queue priority so that we can prioritize specific jobs by pushing to eu-west:high or us-ord:high.
#Making it Work, Slowly
With our Horizon config taken care of, it’s time to test our new multi-region approach. But first, we need to push our jobs to the correct queue.
In our case, we’ve added a new option to the UI so that users can select their desired region for each site. This is stored in the database (as eu-west or us-ord), meaning we can update our dispatch logic to push to their chosen queue, like so:
dispatch($job)->onQueue($site->region);We also need to update every worker server’s .env file to change the APP_ENV value so that it corresponds to the region where the worker is physically located:
APP_ENV=us-ordOne important caveat here (if your jobs are checking the current environment and performing conditional logic) is you need to update the conditionals to include your new environments because they’re technically production:
if (app()->environment(['production', 'us-ord', 'eu-west'])) {
//
}Finally, terminate Horizon on your worker servers so that they pick up their new APP_ENV value and code changes, and start a Horizon process on the app server so that jobs pushed to the default queue continue to be processed.
Once the Horizon processes have restarted, you can test your queues to see if everything works. If you’ve done everything correctly, it should. However, let’s not get ahead of ourselves.
We can’t talk about multi-region applications without considering network latency. You can’t just point an application at a database on the other side of the world and expect everything to be tickety-boo. There are trade-offs.
If you check the processing time of your jobs, you’ll notice that the job execution time is likely much longer in the regions outside your private network. In our case, jobs in the Chicago region were taking 10-20 times longer.
When an application and its database are in different regions, each interaction between them must traverse a greater physical distance, resulting in increased latency. The larger the amount of data, the more latency that occurs. It’s physics.
In the context of a Laravel application, every MySQL and Redis query or command from the Chicago region has to cross the Atlantic Ocean, resulting in a significant increase in round-trip time compared to the London worker servers.
#Refactoring for Network Latency
As mentioned above, our job responsible for auditing a site was doing some heavy lifting and on average, took 10-30 seconds to process, depending on the complexity of the site being audited.
For an idea of what was going on, here’s a slimmed-down version of the job class:
class RunAudit implements ShouldQueue
{
use Dispatchable;
use InteractsWithQueue;
use Queueable;
use SerializesModels;
public function __construct(
public Device $device,
public Run $run,
public Page $page,
) {}
public function handle()
{
$this->run->started();
app(Pipeline::class)
->send([
$this->device,
$this->run,
$this->page
])
->through([
WarmCache::class,
RunLighthouse::class,
SaveReport::class,
SaveAudits::class,
SaveNetworkRequests::class,
SaveWarnings::class,
SaveError::class,
])
->thenReturn();
$this->run->finished();
}
}Needless to say, a lot of database operations were performed during the job’s execution. In particular, the “Save” actions wrote a large amount of data to the database. For instance, the SaveNetworkRequests action would write a row for each network request performed during a page load and include timing data and response headers. That’s a good chunk of data when pages have 100+ network requests.
Let’s make this quicker!
#Identify Multi-Region Requirements
The first thing we need to do is limit the amount of logic performed in the job. That starts with us identifying what needs to be performed by our regional worker servers.
In our case, that’s WarmCache to prime any caches and RunLighthouse which launches Google Chrome and runs a Lighthouse audit. Almost everything else is the processing of the Lighthouse data, which can be performed anywhere—ideally, on our app server, where network latency isn’t an issue. That leaves us with the following stripped-back handle() method:
public function handle()
{
app(Pipeline::class)
->send([
$this->device,
$this->run,
$this->page
])
->through([
WarmCache::class,
RunLighthouse::class,
])
->thenReturn();
}#Eradicate Database Writes
Our new handle() method no longer performs database writes, but we’re also not saving our Lighthouse data anywhere, which is useless. Instead of writing directly to the database, we can upload the Lighthouse JSON data to object storage (we’re using Cloudflare R2). Our app server can then download the file, process it, and save any data to the database.
For this to work, we will fire an AuditFinished event once the job has uploaded the file to storage and attach a queued event listener. This queued listener will be pushed to the default queue and be picked up by the app server for processing:
public function handle()
{
app(Pipeline::class)
->send([
$this->device,
$this->run,
$this->page
])
->through([
WarmCache::class,
RunLighthouse::class,
SaveLighthouseData::class,
])
->thenReturn();
event(new AuditFinished($this->device, $this->run, $this->page);
}Our queued event listener downloads the Lighthouse JSON data from R2, then picks up where the original job left off and processes the data. This is how the listener looks:
class ProcessAudit implements ShouldQueue
{
public function handle(AuditFinished $event)
{
app(Pipeline::class)
->send([
$event->device,
$event->run,
$event->page
])
->through([
DownloadLighthouseData::class,
SaveReport::class,
SaveAudits::class,
SaveNetworkRequests::class,
SaveWarnings::class,
SaveError::class,
DeleteLighthouseData::class,
])
->thenReturn();
}
}As mentioned above, the listener is processed on the app server because it’s now running Horizon and processing the default queue. Instead of taking minutes, processing and saving the report data took milliseconds because there’s no network latency.
#Limit Database Reads
That’s database writes eradicated, but we can improve things further by looking at database reads. Our audit job isn’t directly reading the database; it simply runs Google Lighthouse and uploads the output to Cloudflare R2. However, if you inspect the job using a tool such as Telescope, SQL queries are performed. Why is that?
When you pass an Eloquent model to a job’s constructor, only the model’s identifier is serialized onto the queue via the SerializesModels trait. When the job is pulled from the queue, it retrieves the full model from the database. In our case, this causes 2 database reads:
public function __construct(
public Device $device, // Enum
public Run $run, // Model
public Page $page, // Model
) {}Now that we’ve simplified our RunAudit job, we don’t need the entire models to complete it. We can refactor it so that the job receives only the data it needs, which is pulled directly from Redis when the job is handled. To run an audit, we only need the following:
The page URL being audited
The device being tested (desktop or mobile)
Any request headers
We also need a way to associate the data with a “run”. We’ll pass the run ID to the AuditFinished event so that we know which run we’re working with from the queued listener.
With that in mind, here’s our final job class:
class RunAudit implements ShouldQueue
{
use Dispatchable;
use InteractsWithQueue;
use Queueable;
use SerializesModels;
public function __construct(
public Device $device, // Enum
public string $url,
public array $headers,
public int $runId,
) {}
public function handle()
{
app(Pipeline::class)
->send([
$this->device,
$this->url,
$this->headers,
])
->through([
WarmCache::class,
RunLighthouse::class,
SaveLighthouseData::class,
])
->thenReturn();
event(new AuditFinished($this->runId, $this->device, $this->url);
}
}With that refactor, our audit job no longer performs database reads or writes, which significantly improves the execution time in regions outside of the app server’s region.
We also need to update our ProcessAudit listener accordingly:
class ProcessAudit implements ShouldQueue
{
public function handle(AuditFinished $event)
{
$run = Run::findOrFail($event->runId);
app(Pipeline::class)
->send([
$event->device,
$run,
$event->url,
])
->through([
DownloadLighthouseData::class,
SaveReport::class,
SaveAudits::class,
SaveNetworkRequests::class,
SaveWarnings::class,
SaveError::class,
DeleteLighthouseData::class,
])
->thenReturn();
}
}
That’s a wrap! With some careful consideration, we can now provide fast, reliable audits to users across different regions while keeping our queue processing times down. Before refactoring for network latency, our audit jobs were taking 10-20 times longer in Chicago. An example audit that took 20 seconds in the London region took 230 seconds in Chicago due to all of the database reads and writes. Limiting the logic within the job and removing all database queries reduced the processing time to 23 seconds. That’s a significant improvement!
I hope this article is helpful. Let me know if you have any questions or suggestions for further improvements. Until next time!
Like to add something? Join the discussion on Twitter.